- Research Article
- Open access
- Published:
A Simple Scheme for Constructing Fault-Tolerant Passwords from Biometric Data
EURASIP Journal on Information Security volume 2010, Article number: 819376 (2010)
Abstract
We present a simple combinatorial construction for the mapping of the biometric vectors to short strings, called the passwords. A verifier has to decide whether a given vector can be considered as a corrupted version of the original biometric vector whose password is known or not. The evaluations of the compression factor, the false rejection/acceptance rates, are derived, and an illustration of a possible implementation of the verification algorithm for the DNA data is presented.
1. Introduction
Let us consider the data transmission scheme in Figure 1. The source generates a vector  containing the outcomes of the measurements of some biometric parameters of a user. This vector is encoded as the vector
containing the outcomes of the measurements of some biometric parameters of a user. This vector is encoded as the vector  , called the password of the user, which is stored in the database under the user's name. The password is read from the database upon request and given to the verifier together with the vector
, called the password of the user, which is stored in the database under the user's name. The password is read from the database upon request and given to the verifier together with the vector  generated by some source. The verifier has to check whether the vector
generated by some source. The verifier has to check whether the vector  can be considered as a corrupted version of the vector
can be considered as a corrupted version of the vector  (accept) or not (reject). The decision can be expressed as the value of a Boolean function
(accept) or not (reject). The decision can be expressed as the value of a Boolean function  , and the formal specification of the procedure is an assignment of the functions
, and the formal specification of the procedure is an assignment of the functions


The data transmission scheme designed for the authentication of a user, where  ,
, , and
, and 
The scheme in Figure 1 shows a conventional biometric authentication system [1]. We apply our coding theory approaches [2–4] to find solutions for the following setup.
-
(1)
The length of the binary representation of the password
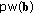 is much less than the length of the vector
is much less than the length of the vector 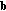 , that is,
, that is, 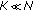 .
. -
(2)
The probability distribution over the vectors
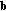 is not given, and the performance is analyzed for the worst assignment of the input data.
is not given, and the performance is analyzed for the worst assignment of the input data. -
(3)
The function
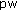 is a deterministic function. Therefore, the distribution of common randomness between the encoder and the verifier, which is a feature of randomized hashing schemes, is not relevant in our case. The probabilities of the incorrect verifier's decisions are computed over the noise ensemble.
is a deterministic function. Therefore, the distribution of common randomness between the encoder and the verifier, which is a feature of randomized hashing schemes, is not relevant in our case. The probabilities of the incorrect verifier's decisions are computed over the noise ensemble. -
(4)
If the vector
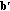 is a corrupted version of the vector
is a corrupted version of the vector  , then the level of noise is measured by the absolute value of the difference of the Hamming weights of the vectors
, then the level of noise is measured by the absolute value of the difference of the Hamming weights of the vectors  and
and 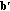 .
.
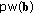 is much less than the length of the vector
is much less than the length of the vector 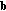 , that is,
, that is, 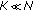 .
.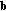 is not given, and the performance is analyzed for the worst assignment of the input data.
is not given, and the performance is analyzed for the worst assignment of the input data.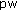 is a deterministic function. Therefore, the distribution of common randomness between the encoder and the verifier, which is a feature of randomized hashing schemes, is not relevant in our case. The probabilities of the incorrect verifier's decisions are computed over the noise ensemble.
is a deterministic function. Therefore, the distribution of common randomness between the encoder and the verifier, which is a feature of randomized hashing schemes, is not relevant in our case. The probabilities of the incorrect verifier's decisions are computed over the noise ensemble.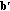 is a corrupted version of the vector
is a corrupted version of the vector  , then the level of noise is measured by the absolute value of the difference of the Hamming weights of the vectors
, then the level of noise is measured by the absolute value of the difference of the Hamming weights of the vectors  and
and 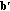 .
.Notice that many authors addressed the problem of constructing fault-tolerant passwords, and the list [5–9] is far from being complete. The main difference of the setup analyzed in our correspondence is the point that the scheme does not require randomization. As a result, our approach can essentially simplify an implementation and simultaneously cause some security problems, which are discussed below.
As  is a deterministic function and the compression factor
is a deterministic function and the compression factor  is large; an attacker, who knows
is large; an attacker, who knows  and wants to pass through the verification stage with the acceptance decision, can easily succeed by generating a vector
and wants to pass through the verification stage with the acceptance decision, can easily succeed by generating a vector  such that
such that  . Therefore, the scheme is not secure in the same sense as the system, which uses the PIN codes of the users: if the PIN code is stolen and the attacker can enter it into the system, then he succeeds. Thus, one needs to encrypt passwords, and our construction can serve as a preliminary step for conventional schemes. Another kind of security is the possibility of guessing the biometric vector on the basis of its password. If the password is the weight of the vector (which is a special case of our construction), then the probability of the correct guess is very small for most of the vectors. However, the weights 0 and
. Therefore, the scheme is not secure in the same sense as the system, which uses the PIN codes of the users: if the PIN code is stolen and the attacker can enter it into the system, then he succeeds. Thus, one needs to encrypt passwords, and our construction can serve as a preliminary step for conventional schemes. Another kind of security is the possibility of guessing the biometric vector on the basis of its password. If the password is the weight of the vector (which is a special case of our construction), then the probability of the correct guess is very small for most of the vectors. However, the weights 0 and  uniquely determine the vector. Thus, meaning the points above, the secrecy of the scheme can be not sufficient for its separate use in practical biometric systems. However, a very large compression factor, very small probabilities of the incorrect verifier's decisions, and very small complexity of the implementation of our scheme that can be attained simultaneously make such a scheme attractive. In particular, we can recommend it for information transmission systems where the verifier has to make only the rejection decision for the vectors
uniquely determine the vector. Thus, meaning the points above, the secrecy of the scheme can be not sufficient for its separate use in practical biometric systems. However, a very large compression factor, very small probabilities of the incorrect verifier's decisions, and very small complexity of the implementation of our scheme that can be attained simultaneously make such a scheme attractive. In particular, we can recommend it for information transmission systems where the verifier has to make only the rejection decision for the vectors  that definitely cannot be considered as corrupted versions of the original biometrical vector. The final decision for the vectors that passed through this test is made by some other tools in this case.
that definitely cannot be considered as corrupted versions of the original biometrical vector. The final decision for the vectors that passed through this test is made by some other tools in this case.
2. Model for the Noise of Observations
We will assume that

where  ,
,  are positive integers and
are positive integers and  is even. Represent the vectors
is even. Represent the vectors  and
and  as concatenations of
as concatenations of  blocks of length
blocks of length  and write
and write

where  for all
for all  . The blocks will be processed in parallel, and we describe the model for the probabilistic transformation of an input block
. The blocks will be processed in parallel, and we describe the model for the probabilistic transformation of an input block  to the received block
to the received block  having the weights
having the weights

If the received block is generated independently of the input block, we assume that  is the value of a random variable having the binomial probability distribution
is the value of a random variable having the binomial probability distribution

where

If the received block is a corrupted version of the input block, we assume that  is the value of a random variable having the given conditional probability distribution
is the value of a random variable having the given conditional probability distribution

Examples 2.
-
(1)
Binary symmetric channel.
Suppose that the vector  is the outcome of a binary symmetric channel having the crossover probability
is the outcome of a binary symmetric channel having the crossover probability  when the vector
when the vector  was sent. Then,
was sent. Then,

-
(2)
The insertion/deletion channel.
Let  . For all
. For all  , let
, let

be the probability that  components of the vector
components of the vector  are noiselessly transmitted, while the remaining
are noiselessly transmitted, while the remaining  positions are filled with an arbitrary vector generated with the probability
positions are filled with an arbitrary vector generated with the probability  . Then,
. Then,  is expressed by (8) with
is expressed by (8) with  substituted for
substituted for  .
.
In the following numerical illustrations, we assume that the conditional probabilities  ,
,  are defined by (8).
are defined by (8).
Discussion over the Model
As the input vector  is fixed, the vector
is fixed, the vector  is also fixed. Given an acceptance set, the probability that the verifier makes an incorrect rejection decision can be computed after the conditional probabilities
is also fixed. Given an acceptance set, the probability that the verifier makes an incorrect rejection decision can be computed after the conditional probabilities  are specified. However, one cannot compute the probability that the verifier makes an incorrect acceptance decision for the best strategy of an attacker, unless the probability distribution over the input vectors (which determines the probability distribution over passwords) is given. We can only compute this probability for a blind attacker, who generates the vector
are specified. However, one cannot compute the probability that the verifier makes an incorrect acceptance decision for the best strategy of an attacker, unless the probability distribution over the input vectors (which determines the probability distribution over passwords) is given. We can only compute this probability for a blind attacker, who generates the vector  by flipping a fair coin, which results in the binomial probability distribution over passwords
by flipping a fair coin, which results in the binomial probability distribution over passwords  . Then, computations become equivalent to the estimation of the ratios of the cardinalities of the sets of input vectors with coinciding passwords and
. Then, computations become equivalent to the estimation of the ratios of the cardinalities of the sets of input vectors with coinciding passwords and  . Notice that this estimation is a typical problem when universal hashing schemes are studied [10]. Since our scheme is oriented to the preprocessing of the pairs of received vectors, the performance of the scheme for a blind attacker is also of interest for practical biometric applications.
. Notice that this estimation is a typical problem when universal hashing schemes are studied [10]. Since our scheme is oriented to the preprocessing of the pairs of received vectors, the performance of the scheme for a blind attacker is also of interest for practical biometric applications.
3. Description of the Verification Scheme
Given the vectors  and
and  , let
, let  and
and  , where components of the vectors
, where components of the vectors  and
and  are defined as
are defined as  and
and  for all
for all  . Thus,
. Thus,

For all vectors  , let
, let  be a subset of vectors of the length
be a subset of vectors of the length  whose components belong to the alphabet
whose components belong to the alphabet  , which is called the acceptance set and associated with the following decoding rule:
, which is called the acceptance set and associated with the following decoding rule:

The verification scheme is illustrated in Figure 2.

The structure of the verification scheme.
Notice that the compression factor, defined as the ratio of the length of the biometric vector and the length of the corresponding password, is equal to

and it does not depend on  .
.
The possible verification errors are the false rejection of the identical biometric entity and the false acceptance of the different biometric entity. The probabilities of these events, called the false rejection and the false acceptance rates, can be expressed as

where

The false rejection event corresponds to the case when the blocks of the input biometric vector are transmitted over a channel in such a way that weights of these blocks are transformed to the weights of the received blocks by a memoryless channel specified by the conditional probabilities  . The false acceptance event corresponds to the case when the blocks of the received vector are generated by a Bernoulli source having the probabilities of zeroes and ones equal to
. The false acceptance event corresponds to the case when the blocks of the received vector are generated by a Bernoulli source having the probabilities of zeroes and ones equal to  .
.
The goals of the designer of the system can be different. In particular, the acceptance set  can be assigned according to the maximum likelihood decision rule. Another assignment is oriented to the minimization of the absolute value of the difference of
can be assigned according to the maximum likelihood decision rule. Another assignment is oriented to the minimization of the absolute value of the difference of  and
and  . Furthermore, this set can be assigned in such a way that the false rejection/acceptance rate is fixed and the false acceptance/rejection rate is minimized. We will present the assignments of the decision sets that provide us with small decoding error probabilities of both types, which makes efficient solutions to the above problems possible.
. Furthermore, this set can be assigned in such a way that the false rejection/acceptance rate is fixed and the false acceptance/rejection rate is minimized. We will present the assignments of the decision sets that provide us with small decoding error probabilities of both types, which makes efficient solutions to the above problems possible.
Our main claim can be summarized as follows.
Theorem 1.
The decision sets  ,
,  , can be assigned in such a way that the scheme has the following features:
, can be assigned in such a way that the scheme has the following features:
-
(a)
the compression factor
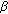 is expressed by (12), and it tends to 0 as an almost linear function of
is expressed by (12), and it tends to 0 as an almost linear function of  independently of
independently of 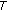 , and
, and -
(b)
the false acceptance and the false rejection rates tend to 0 as exponential functions of
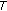 in such a way that
in such a way that 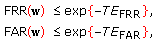 (15)
(15)
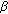 is expressed by (12), and it tends to 0 as an almost linear function of
is expressed by (12), and it tends to 0 as an almost linear function of  independently of
independently of 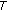 , and
, and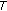 in such a way that
in such a way that 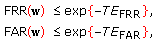
and  tend to constants depending only on
tend to constants depending only on  , as
, as  increases.
increases.
The (a) part of the claim directly follows from the description of the scheme. The (b) part of the claim follows from the analysis presented in Section 5. Notice that the fact that the probabilities of error exponentially vanish with  when the expected values of the corresponding random variables differ is a classical result of detection and estimation theory [11]. We will meet the situation of coinciding expected values, and such a behavior is attained due to the difference of the variances of these variables.
when the expected values of the corresponding random variables differ is a classical result of detection and estimation theory [11]. We will meet the situation of coinciding expected values, and such a behavior is attained due to the difference of the variances of these variables.
Let us first discuss possible approaches to constructing verification schemes for the noiseless case  when the biometric vectors are mapped to passwords by a deterministic function. In this case, the verifier constructs the password for the vector
when the biometric vectors are mapped to passwords by a deterministic function. In this case, the verifier constructs the password for the vector  and makes the acceptance decision if and only if it coincides with the password associated with the claimed user. As a result, the false rejection rate is equal to 0: if
and makes the acceptance decision if and only if it coincides with the password associated with the claimed user. As a result, the false rejection rate is equal to 0: if  , then the passwords are identical.
, then the passwords are identical.
Suppose that the password is defined as a binary vector of length  where the
where the  th bit is the parity of the
th bit is the parity of the  th block of the vector
th block of the vector  (the
(the  th bit of the password is equal to 1 if and only if the weight of the vector
th bit of the password is equal to 1 if and only if the weight of the vector  is odd),
is odd),  . Then, the compression factor is equal to
. Then, the compression factor is equal to  and the false acceptance rate is equal to
and the false acceptance rate is equal to  , that is, the scheme has a similar features as our scheme. However, to attain a large compression factor for
, that is, the scheme has a similar features as our scheme. However, to attain a large compression factor for  , one needs a very large
, one needs a very large  to obtain low false rejection and false acceptance rates. Another approach to the verification for the noiseless case is based on the specification of the password as a vector consisting of weights of the blocks. Then, the compression factor is equal to
to obtain low false rejection and false acceptance rates. Another approach to the verification for the noiseless case is based on the specification of the password as a vector consisting of weights of the blocks. Then, the compression factor is equal to  while the false acceptance rate is equal to
while the false acceptance rate is equal to

It decreases with  as an exponential function and decreases with
as an exponential function and decreases with  as a polynomial function. We claim that a similar conclusion is also valid for
as a polynomial function. We claim that a similar conclusion is also valid for  .
.
4. Processing the 1-Block Vectors
Suppose that  , denote
, denote  ,
,  , and use the notation (4). We also write
, and use the notation (4). We also write  and represent (11) as
and represent (11) as

The maximum likelihood decision rule is implemented by using the acceptance set

Then, the false rejection and the false acceptance rates are expressed as

where  and
and  are the minimum integers satisfying the inequalities
are the minimum integers satisfying the inequalities  and
and  .
.
To check the (b) claim of the theorem, we use the Gaussian approximations


where

stands for the Gaussian probability density function with the mean  and the variance
and the variance  . The convergence (21) is the standard Gaussian approximation for the binomial distribution. The convergence (20) follows from
. The convergence (21) is the standard Gaussian approximation for the binomial distribution. The convergence (20) follows from

for all  . Furthermore, the replacement of the sum over
. Furthermore, the replacement of the sum over  at the right-hand side of (8) with the integral over
at the right-hand side of (8) with the integral over  taken over the interval
taken over the interval  results in (20).
results in (20).
In particular,  and
and  are two Gaussian probability density functions having the same mean
are two Gaussian probability density functions having the same mean  and different variances equal to
and different variances equal to  and
and  , respectively. The maximum likelihood decoding in this case is equivalent to the selection of one of two hypotheses about the variance of the Gaussian probability distributions having the same mean. It is well known (see, for example [12]) that the probabilities of the incorrect decisions are determined by the ratio of variances, which is equal to
, respectively. The maximum likelihood decoding in this case is equivalent to the selection of one of two hypotheses about the variance of the Gaussian probability distributions having the same mean. It is well known (see, for example [12]) that the probabilities of the incorrect decisions are determined by the ratio of variances, which is equal to  and does not depend on
and does not depend on  .
.
The simplest upper bound for the false acceptance and the false rejection rates can be expressed using the Bhattacharyya distance [13] between the probability density functions  and
and  . Namely, denote
. Namely, denote

where

Examples of the probability density functions  and
and  are given in Figure 3 where we also show the false rejection and the acceptance rates for the maximum likelihood decision rule.
are given in Figure 3 where we also show the false rejection and the acceptance rates for the maximum likelihood decision rule.

Example of the probability distributions  and
and 
The values of  ,
,  can be bounded from above as
can be bounded from above as

The inequalities (26) follow from the observations

The multiplications of the probabilities  and
and  in (24) by the square roots above and extension of the integration over all possible values of
in (24) by the square roots above and extension of the integration over all possible values of  bring the desired bounds.
bring the desired bounds.
The value of the integral at the right-hand side of (26) can be easily computed using the statement below.
Proposition 1.
For all pairs  and
and  such that
such that  ,
,

The proof is given in the Appendix.
The use of (28) with  and
and  shows that the worst case corresponds to
shows that the worst case corresponds to  and
and

where

The bounds (29) are very simple, but they can be useless. For example, if  , then
, then  . If the acceptance set for the vector
. If the acceptance set for the vector  consisting of
consisting of  blocks is defined as the set of vectors
blocks is defined as the set of vectors  such that
such that  for at least
for at least  indices
indices  and the estimate of the probability of incorrect decision for each block is greater than
and the estimate of the probability of incorrect decision for each block is greater than  , then the estimate of probability of incorrect decision for
, then the estimate of probability of incorrect decision for  blocks is close to 1. Nevertheless, if the acceptance set is defined differently, considerations of this section are of interest.
blocks is close to 1. Nevertheless, if the acceptance set is defined differently, considerations of this section are of interest.
5. Processing the  -Block Vectors
-Block Vectors
 -Block Vectors
-Block VectorsLet us first summarize our verification scheme, which can be also called a basic scheme.
Enrollment. Represent the input vector  of length
of length  as a result of concatenation of
as a result of concatenation of  blocks of length
blocks of length  . Compute the weights of the blocks
. Compute the weights of the blocks  and store them in the database as the vector
and store them in the database as the vector  .
.
Verification. Having received a binary vector  , construct the vector of weights of its blocks and denote this vector by
, construct the vector of weights of its blocks and denote this vector by  . Compute
. Compute

and make the acceptance decision if the obtained value is greater than a fixed threshold  that has to be chosen in advance depending on the requirements to the false acceptance and the false rejection rates, that is,
that has to be chosen in advance depending on the requirements to the false acceptance and the false rejection rates, that is,

We write

when  are defined by (13) with the set
are defined by (13) with the set  substituted for the set
substituted for the set  . Let us also denote
. Let us also denote

where

The probabilities introduced above can be easily estimated for  , which corresponds to the maximum likelihood decision rule. Namely,
, which corresponds to the maximum likelihood decision rule. Namely,

where


where  is defined in (30). Hence,
is defined in (30). Hence,  is a lower bound on the exponents
is a lower bound on the exponents in(15).
in(15).
Let us denote

Then, the inequalities (36) can be represented as the following statement: if  , then
, then

Similarly, the inequalities (38) can be represented as the following statement: if  , then
, then

Some values of  and
and  are given in Table 1.
are given in Table 1.
 and
and  .
.Suppose that the biometric vectors have length  . Let us partition this length in
. Let us partition this length in  blocks of length
blocks of length  (we will refer to the corresponding line in Table 1). In our scheme, each block is mapped to a binary vector of length
(we will refer to the corresponding line in Table 1). In our scheme, each block is mapped to a binary vector of length  , and the length of the password is equal to
, and the length of the password is equal to  . The compression factor is equal to
. The compression factor is equal to  . Suppose that
. Suppose that  . Then, the expected number of errors when the biometric vector is corrupted is equal to
. Then, the expected number of errors when the biometric vector is corrupted is equal to  , which is 5.6 times greater than the length of the password. Nevertheless, we attain the false rejection and the false acceptance rates not greater than
, which is 5.6 times greater than the length of the password. Nevertheless, we attain the false rejection and the false acceptance rates not greater than  . Furthermore, if
. Furthermore, if  is increased twice and becomes equal to 256 (the length of the vectors is equal to
is increased twice and becomes equal to 256 (the length of the vectors is equal to  , then the false rejection and the false acceptance rates are not greater than
, then the false rejection and the false acceptance rates are not greater than  . Similar conclusions can be drawn for any length in a way that the increase of the length by 14 blocks reduces the false rejection and the false acceptance rates 10 times. If
. Similar conclusions can be drawn for any length in a way that the increase of the length by 14 blocks reduces the false rejection and the false acceptance rates 10 times. If  or
or  , then we have to substitute 4.31 or 35.94 for 14.06 in these considerations. Notice also that these numbers are very close to the numbers that are asymptotically attained and have a simple formal expression.
, then we have to substitute 4.31 or 35.94 for 14.06 in these considerations. Notice also that these numbers are very close to the numbers that are asymptotically attained and have a simple formal expression.
6. A Variant of the Verification Scheme Based on Balancing
For all  , let
, let  denote the vector constructed by the concatenation of
denote the vector constructed by the concatenation of  ones and
ones and  zeroes. For example, if
zeroes. For example, if  , then
, then

The vector  is called a balanced vector if it contains equal number of zeroes and ones. Thus, the weight of a balanced vector is equal to
is called a balanced vector if it contains equal number of zeroes and ones. Thus, the weight of a balanced vector is equal to  .
.
Given a vector  , let
, let

denote the set of indices  such that the transformation
such that the transformation

which inverts the first  components of the vector
components of the vector  , brings a balanced vector. For example,
, brings a balanced vector. For example,

The transformation (44) is illustrated in Table 2.
 , where
, where  .
.It is well known [14] that

Introduce the following algorithm.
Enrollment. Represent the input vector  of length
of length  as a result of concatenation of
as a result of concatenation of  blocks of length
blocks of length  . For each block
. For each block  , construct the set
, construct the set  and choose an integer
and choose an integer  according to a uniform probability distribution over the set
according to a uniform probability distribution over the set  . Set
. Set

and store the vector  in the database.
in the database.
Verification. Represent the input vector  of length
of length  as a result of concatenation of
as a result of concatenation of  blocks of length
blocks of length  . For each block
. For each block  , compute
, compute

Make the acceptance decision if and only if  , where
, where  is the vector whose components are equal to
is the vector whose components are equal to  and the acceptance set
and the acceptance set  is defined in (32).
is defined in (32).
For example, if  , then the vector 0000 is mapped to the password "2", the vector 0101 is mapped to the passwords "0", "2", "4" with the probabilities
, then the vector 0000 is mapped to the password "2", the vector 0101 is mapped to the passwords "0", "2", "4" with the probabilities  , and the vector 0100 is mapped to the passwords "1", "3" with probability
, and the vector 0100 is mapped to the passwords "1", "3" with probability  .
.
Proposition 2.
Let a given vector  be transmitted over a binary symmetric channel having the crossover probability
be transmitted over a binary symmetric channel having the crossover probability  , that is, the conditional probability of receiving the vector
, that is, the conditional probability of receiving the vector  at the output of the channel is expressed as
at the output of the channel is expressed as

If  is assigned in such a way that
is assigned in such a way that  is the balanced vector and
is the balanced vector and

denote the probability of receiving a vector  with
with

then

The proof is given in the Appendix.
An idea of the introduction of the balanced scheme is to reduce the performance of the verifier to the worst case performance for the basic scheme when all components of the vector  are equal to
are equal to  . Another disadvantage of the scheme is the point that an attacker passes through the verification stage with the acceptance decision by presenting an alternating vector
. Another disadvantage of the scheme is the point that an attacker passes through the verification stage with the acceptance decision by presenting an alternating vector  . On the other hand, the balancing scheme allows us to hide any biometric vector of the user in his password, contrary to the basic scheme where the password consisting of all zeroes discovers the original vector. Furthermore, in most of the cases the same biometric vector can be mapped to many different passwords, since the mapping is stochastic when the cardinality of at least one of the sets
. On the other hand, the balancing scheme allows us to hide any biometric vector of the user in his password, contrary to the basic scheme where the password consisting of all zeroes discovers the original vector. Furthermore, in most of the cases the same biometric vector can be mapped to many different passwords, since the mapping is stochastic when the cardinality of at least one of the sets  is greater than 1.
is greater than 1.
The conclusion about the secrecy of the balanced scheme, meaning the possibility of the discovery of the block given its password, is based on the considerations below. Given an  , let
, let

Then (see Table 2),

where the first inequality follows from the observation that  specifies one of terms of the sum for any
specifies one of terms of the sum for any  . Hence, the total number of biometric vectors that are mapped to the same password is bounded from below as
. Hence, the total number of biometric vectors that are mapped to the same password is bounded from below as

and the exponent asymptotically coincides with  .
.
7. Example of Using the Verification Scheme for the DNA Data
There are data received on the basis of the DNA measurements [15]. We previously used them to illustrate coding schemes in [16, 17].
The example, described in this section, is mainly introduced for the illustration, since the performance of the verifier probably does not allow one to recommend it for practical use. Nevertheless, transformations of the outcomes of the measurements seem to be typical. Notice also that the DNA data are universal in a sense that there are 24–28 deciphered alleles where the corresponding probability distributions of the outcomes of the measurements are recognized as stable distributions, while processing fingerprints, iris, and so forth requires the description of a number of technical details.
7.1. Structure of the DNA Data and the Mathematical Model
The most common DNA variations are Short Tandem Repeats (STR), arrays of 5 to 50 copies (repeats) of the same pattern (the motif) of 2 to 6 pairs. As the number of repeats of the motif highly varies among individuals, it can be effectively used for identification of individuals. The human genome contains several 100,000 STR loci, that is, physical positions in the DNA sequence where an STR is present. An individual variant of an STR is called allele. Alleles are denoted by the number of repeats of the motif. The genotype of a locus comprises both the maternal and the paternal allele. However, without additional information, one cannot determine which allele resides on the paternal or the maternal chromosome. If the measured numbers are equal to each other, then the genotype is called homozygous. Otherwise, it is called heterozygous. The STR measurement errors are usually classified into three groups: (1)allelic drop-in, when in a homozygous genotype, an additional allele is erroneously included, for example, genotype (10,10) is measured as (10,12); (2)allelic drop–out, when an allele of a heterozygous genotype is missing, for example, genotype (7,9) is measured as (7,7); (3)allelic shift, when an allele is measured with a wrong repeat number, for example, genotype (10,12) is measured as (10,13).
The points above can be formalized as follows [16]. Suppose that there are  sources. Let the
sources. Let the  th source generate a pair of integers according to the probability distribution
th source generate a pair of integers according to the probability distribution

where  and
and  ,
,  are given positive integers. Thus,we assume that
are given positive integers. Thus,we assume that and
and are independent random variables that contain information about the number of repeats of the
are independent random variables that contain information about the number of repeats of the  th motif in the maternal and the paternal allele. We also assume that
th motif in the maternal and the paternal allele. We also assume that ,
, ,are mutually independent pairs of random variables, that is,
,are mutually independent pairs of random variables, that is,

where  and
and  ,
, .
.
Let us fix a  and denote
and denote

Then, the probability distribution of a pair of random variables

which represents the outcome of the  th measurement, can be expressed as
th measurement, can be expressed as

where  , if
, if  , and
, and  , if
, if  . Thus, the total number of outcomes having positive probability is equal to
. Thus, the total number of outcomes having positive probability is equal to

7.2. Mapping of the DNA Data to Binary Vectors and Introducing the Passwords
The outcomes of the DNA measurements bring the following results [16]: the total number of alleles is 28, one can extract 128 bits from the measurements of a person, the entropy of the probability distribution over the outcomes is equal to 109, and the maximum probability of a vector consisting of 28 outcomes is equal to  . In the following discussion, we will assume that
. In the following discussion, we will assume that  (theDYS391 allele is excluded).
(theDYS391 allele is excluded).
Let us fix  and let
and let  denote the set of cardinality
denote the set of cardinality  consisting of the outcomes that can be received from the
consisting of the outcomes that can be received from the  -th allele with positive probability. Associate the outcomes with the integers
-th allele with positive probability. Associate the outcomes with the integers  and let
and let  denote the probability of the outcome, which is mapped to the integer
denote the probability of the outcome, which is mapped to the integer  . Let us run the procedure that maps
. Let us run the procedure that maps  to the integer
to the integer  partition the set
partition the set  in 8 subsets
in 8 subsets  in such a way that
in such a way that

and set

The use of this procedure for  maps 27 outcomes to a vector
maps 27 outcomes to a vector  , which can be expressed by a binary vector
, which can be expressed by a binary vector  .
.
Let us apply the verification scheme described in Section 3 for  and
and  . Thus, the vector
. Thus, the vector  is mapped to the password
is mapped to the password  , where
, where  , and we need 15 bits to express a password in binary format. Furthermore, let us postulate the following model for the noise when the DNA data of the same user are measured for the second time: with probability
, and we need 15 bits to express a password in binary format. Furthermore, let us postulate the following model for the noise when the DNA data of the same user are measured for the second time: with probability  , the outcome of the measurement at the
, the outcome of the measurement at the  th allele is the same as before; with probability
th allele is the same as before; with probability  , it is equal to the integer
, it is equal to the integer  chosen from the set
chosen from the set  according to a uniform probability distribution. In the following formal considerations, we assume a simplified model where the approximate equality(62)is replaced with the equality for all
according to a uniform probability distribution. In the following formal considerations, we assume a simplified model where the approximate equality(62)is replaced with the equality for all and
and .One also assumes that the outcome of the measurement of the same user copies the previous value of
.One also assumes that the outcome of the measurement of the same user copies the previous value of with probability
with probability and that it takes an arbitrary value belonging to the set
and that it takes an arbitrary value belonging to the set with probability
with probability ,where
,where is less than
is less than . In a practical system,
. In a practical system,  [15], we set
[15], we set  . Notice that our assumptions do not seem to be critical: after these assumptions are relaxed, the formal analysis below has to be updated with the correction factors without essential change of the conclusions.
. Notice that our assumptions do not seem to be critical: after these assumptions are relaxed, the formal analysis below has to be updated with the correction factors without essential change of the conclusions.
For  , set
, set

and, for  and
and  , set
, set

Then,  is equal to the probability of the event that "the weights of the
is equal to the probability of the event that "the weights of the  th DNA measurements" of a randomly chosen person are equal to
th DNA measurements" of a randomly chosen person are equal to  and
and  at the enrollment and the verification stages, respectively,
at the enrollment and the verification stages, respectively,  .
.
To express the conditional probabilities  ,
,  ,
,  , 27, run the following procedure.
, 27, run the following procedure.
-
(1)
For
 , set
, set  (66)
(66)
 , set
, set 
-
(2)
For
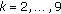 ,
,-
(a)
for
 , set
, set -
(b)
for
 and
and  , increase
, increase  by the product
by the product 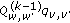 , that is, set
, that is, set
-
(a)
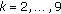 ,
, , set
, set and
and  , increase
, increase  by the product
by the product 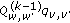 , that is, set
, that is, set

-
(3)
For
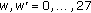 , set
, set 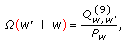 (69)
(69)
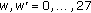 , set
, set 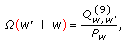
where

One can see that the same procedure, being used with  , gives the entries of the probabilities
, gives the entries of the probabilities  ,
,  , that describe the output probability distribution for the attacker (the value of parameter
, that describe the output probability distribution for the attacker (the value of parameter  is arbitrary in this case). The obtained probability distributions bring all necessary data for the verification algorithm of the previous section when
is arbitrary in this case). The obtained probability distributions bring all necessary data for the verification algorithm of the previous section when  and
and

Some data are presented in Table 3 where we show only the entries of the probability distributions that are greater than 0.01.
 and for the attacker
and for the attacker  .
.The data processing above illustrates several points that can be important for the practical implementation of the verification algorithm. In particular, notice that the conditional probability distributions  ,
, , were introduced using the input probability distributions, but they are almost independent on
, were introduced using the input probability distributions, but they are almost independent on  and their approximation,
and their approximation,  ,
, , can be assigned only as the function of
, can be assigned only as the function of  ,
,

for  . The verification algorithm can be simplified in such a way that the acceptance decision is made if and only if
. The verification algorithm can be simplified in such a way that the acceptance decision is made if and only if  for
for  . Then, the false rejection rate is approximated as
. Then, the false rejection rate is approximated as

and the false acceptance rate is approximated as

This value has to be multiplied by a factor having the order of magnitude of  if one is interested in the average false acceptance rate. Notice also that the mapping (63) gives an additional resource that decreases the false acceptance rate: if we randomize over the mapping for
if one is interested in the average false acceptance rate. Notice also that the mapping (63) gives an additional resource that decreases the false acceptance rate: if we randomize over the mapping for  , then the same factor of the false acceptance rate is obtained for a fixed input vector consisting of pairs of outcomes of the DNA measurements.
, then the same factor of the false acceptance rate is obtained for a fixed input vector consisting of pairs of outcomes of the DNA measurements.
Our example also indicates the point that the mapping of the available data to a binary string with the further computation of the weight of the vector looks as an artificial transformation, and "a more natural password" would be specified as the arithmetic average of 9 integers that form the block. However, the arithmetic average is a float, and we also meet a problem of the specification of the length of a binary string needed for its representation (it also determines the length of the password in bits). We plan to discuss this point in a future correspondence.
8. Conclusion
We presented some variants of the verification schemes oriented to practical applications where the original biometric vectors are split into blocks and converted to short strings using block-by-block transformations. The key idea is the translation of the statistical dependence between the vectors of the same user into the statistical dependence between passwords assigned to the corresponding blocks. The scheme can be introduced without assumptions about a coordinate—wise dependence between the biometric vectors, which is important for many practical applications, like processing of the iris or fingerprints. In general case, "the weight of the block" is the function of the total amount of information extracted from a fixed number of outcomes of the measurements. In particular, it can be understood as the number of minutiae points belonging to a certain area while measuring the fingerprint. Different types of the observation errors, and like missing of some data, registration errors, synchronization errors, are also accumulated. To implement the verification algorithm, one is supposed to find a proper description of the conditional probability distribution  without specification of the errors that cause the corresponding transitions. This problem is oriented to a particular application, since we do not think that there exists a universal procedure for any biometric observations. The analysis presented in our correspondence can serve as a basis for the analysis of the verification performance depending on this probability distribution.
without specification of the errors that cause the corresponding transitions. This problem is oriented to a particular application, since we do not think that there exists a universal procedure for any biometric observations. The analysis presented in our correspondence can serve as a basis for the analysis of the verification performance depending on this probability distribution.
Notice that the verification scheme can be also effectively used when the name of a person, which is used as a pointer to a particular password stored in the database, is not given. In this case, our approach serves as a filter to make a preselection of passwords of the users whose biometric vectors can be close to the presented biometric vector. As a result, we get a typical application of hashing when the rejection decision are made with the data that are stored in a random access memory.
Notice also that there are different variants of the basic procedure. One of them, called the balancing verification scheme, was described. Another variant appears with non-uniform partitioning of the biometric vectors in blocks. In this case, the blocks of lengths  are created in such a way that their weights are shifted from
are created in such a way that their weights are shifted from  "as much as possible" to improve the performance. However, the positions of the boundaries of the blocks have to be stored, and one has to investigate the tradeoff between the performance and the required size of the memory. We did not consider this problem in the present correspondence assuming that the length of the original biometric vector and the length of the password are fixed. In this case, for the basic scheme, the values of
"as much as possible" to improve the performance. However, the positions of the boundaries of the blocks have to be stored, and one has to investigate the tradeoff between the performance and the required size of the memory. We did not consider this problem in the present correspondence assuming that the length of the original biometric vector and the length of the password are fixed. In this case, for the basic scheme, the values of  and
and  are fixed, and the values of the parameters
are fixed, and the values of the parameters  and
and  are determined.
are determined.
Appendix
A. Proof of Proposition 1
We write

and use the equalities

Therefore,

B. Proof of Proposition 2
We write

where  ,
, , and (52) follows.
, and (52) follows.
References
Bolle RM, Connell JH, Pankanti S, Ratha NK, Senior AW: Guide to Biometrics. Springer, New York, NY, USA; 2004.
Balakirsky VB: Hashing of databases with the use of metric properties of the hamming space. Computer Journal 2005, 48(1):4-16. 10.1093/comjnl/bxh059
Balakirsky VB, Ghazaryan AR, Han Vinck AJ: Estimating the Hamming distance between binary vectors via rate distortion source coding. Proceedings of the 29th Symposium on Information Theory in the Benelux, 2008, Leuven, Belgium 3-10.
Balakirsky VB, Ghazaryan AR, Han Vinck AJ: Combinatorial data reduction algorithm and its applications to biometric verification. Proceedings of the IEEE International Symposium on Information Theory (ISIT '09), 2009, Seoul, Korea 2246-2251.
Uludag U, Pankanti S, Prabhakar S, Jain AK: Biometric cryptosystems: Issues and challenges. Proceedings of the IEEE 2004, 92(6):948-60.
Ratha N, Chikkerur S, Connell J, Bolle R: Security with Noisy Data. Springer, New York, NY, USA; 2007.
Juels A, Wattenberg M: Fuzzy commitment scheme. Proceedings of the 6th ACM Conference on Computer and Communications Securit, November 1999 28-36.
Dodis Y, Reyzin L, Smith A: Fuzzy extractors: how to generate strong keys from biometrics and other noisy data. Lecture Notes in Computer Science 2004, 3027: 523-540. 10.1007/978-3-540-24676-3_31
Frykholm N, Juels A: Error-tolerant password recovery. Proceedings of the 8th ACM Conference on Computer and Communications Security, 2001, Philadelphia, Pa, USA 1-9.
Stinson DR: Universal hashing and authentication codes. Designs, Codes and Cryptography 1994, 4(3):369-380. 10.1007/BF01388651
Van Trees HL: Detection, Estimation and Modulation Theory. John Wiley & Sons, New York, NY, USA; 2002.
Papoulis A: Papoulis, Probability, Random Variables and Stochastic Processes. McGraw-Hill, New York, NY, USA; 1984.
Gallager R: Information Theory and Reliable Communication. John Wiley & Sons, New York, NY, USA; 1986.
Knuth DE: Efficient balanced codes. IEEE Transactions on Information Theory 1986, 32(1):51-53. 10.1109/TIT.1986.1057136
Korte U, Krawczak M, Merkle J, et al.: A cryptographic biometric authentication system based on genetic fingerprints. Proceedings of the Sicherheit, 2008, Saarbrucken, Germany 263-276.
Balakirsky VB, Ghazaryan AR, Han Vinck AJ: Additive block coding schemes for biometric authentication with the DNA data. In Proceedings of the 1st European Workshop on Biometrics and Identity Management, 2008, Lecture Notes in Computer Science Edited by: Schouten Bet al.. 5372: 160-169.
Balakirsky VB, Han Vinck AJ: Mathematical model for constructing passwords from biometrical data. Security and Communication Networks 2009, 2(1):1-9. 10.1002/sec.96
Acknowledgment
This work was partially supported by the DFG.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Balakirsky, V., Vinck, A. A Simple Scheme for Constructing Fault-Tolerant Passwords from Biometric Data. EURASIP J. on Info. Security 2010, 819376 (2010). https://doi.org/10.1155/2010/819376
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/819376